教你用Python写脚本,抓取百度百科最新内容!
你是否曾想过,每当你需要最新的百科信息时,手动查找好像有点慢?而且那些无数个百度百科的页面,如何才能快速收集到呢?其实,借助的一段简单脚本,你就能快速完成任务!
今天,就让我们一起用写一个简单的爬虫,抓取百度百科的最新内容!只需要几行代码,你就能轻松获取任何你感兴趣的词条,速度快、准确又高效,简直是程序员的必备技能!
准备工作:安装必要的库
开始之前,我们需要先安装一些库,以便抓取数据。常用的库有:
首先,打开命令行,执行以下命令来安装:
第一步:获取网页内容
首先,我们需要通过库来发送HTTP请求,获取百度百科上某个词条的页面内容。比如我们要抓取“”这个词条。

这段代码简单明了,通过.get(url)获取网页内容。接下来,我们可以使用来解析这些内容。
第二步:解析网页内容
接下来,借助解析HTML,抓取我们需要的部分。假设我们只想提取百科页面的摘要部分。

第三步:改进抓取逻辑,提取更多内容
你会发现,百度百科的页面除了摘要外,还有很多其他内容,像是图片、视频等。我们可以根据需要提取更多的信息。
例如,提取该词条下所有的段落内容:

代码会输出百科页面的每段文本,您可以根据实际需求进一步改进,抓取更详细的数据。
第四步:处理请求失败和延迟
爬虫在抓取网页过程中,可能面临诸如网页加载失败或请求频繁被封禁的问题。为了防止被封禁,我们可以在每次请求时模拟浏览器,并插入延时来减缓请求频率。
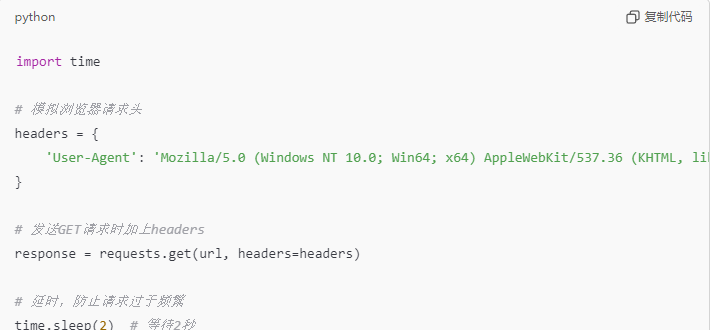
这样做能有效防止因过度请求而导致的封禁。
总结:
你看,抓取百度百科内容其实没有那么复杂,关键在于掌握几个常用的工具——用来获取页面内容,用来解析网页数据,再加上一些简单的处理逻辑,就能快速提取你需要的信息。
只要这几行代码,你就能从百度百科抓取任何你感兴趣的词条内容!切记,在抓取内容时遵守相关使用规则,并尊重版权及隐私。
想让这个脚本更强大吗?你可以让它定期抓取最新内容、保存到本地文件、甚至制作一个爬虫爬取整个百科分类。更多有趣的功能,只等你来探索!
快来尝试一下, 和我一起用探索更多有趣的数据吧!

